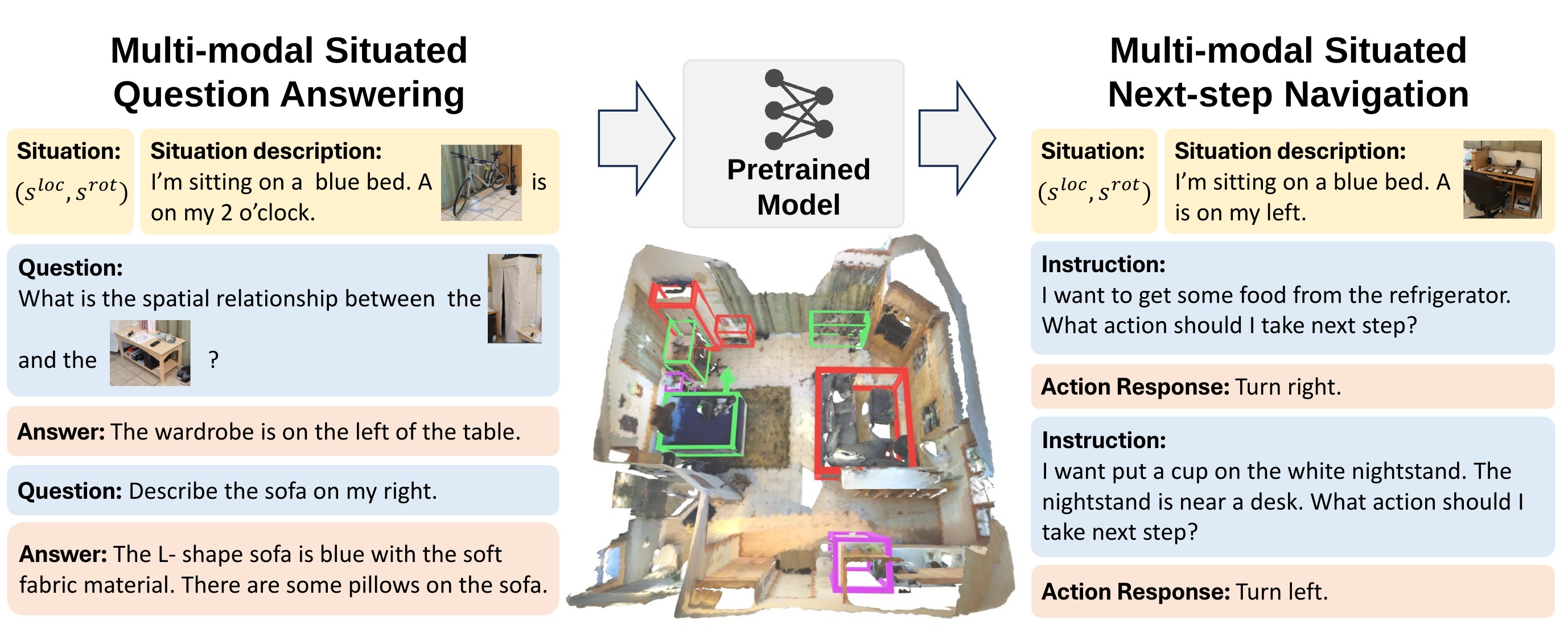
Benchmarks
An overview of benchmarking tasks in MSR3D. We use green boxes for objects mentioned in situation descriptions, red for objects in questions, and purple for objects in navigation instructions.
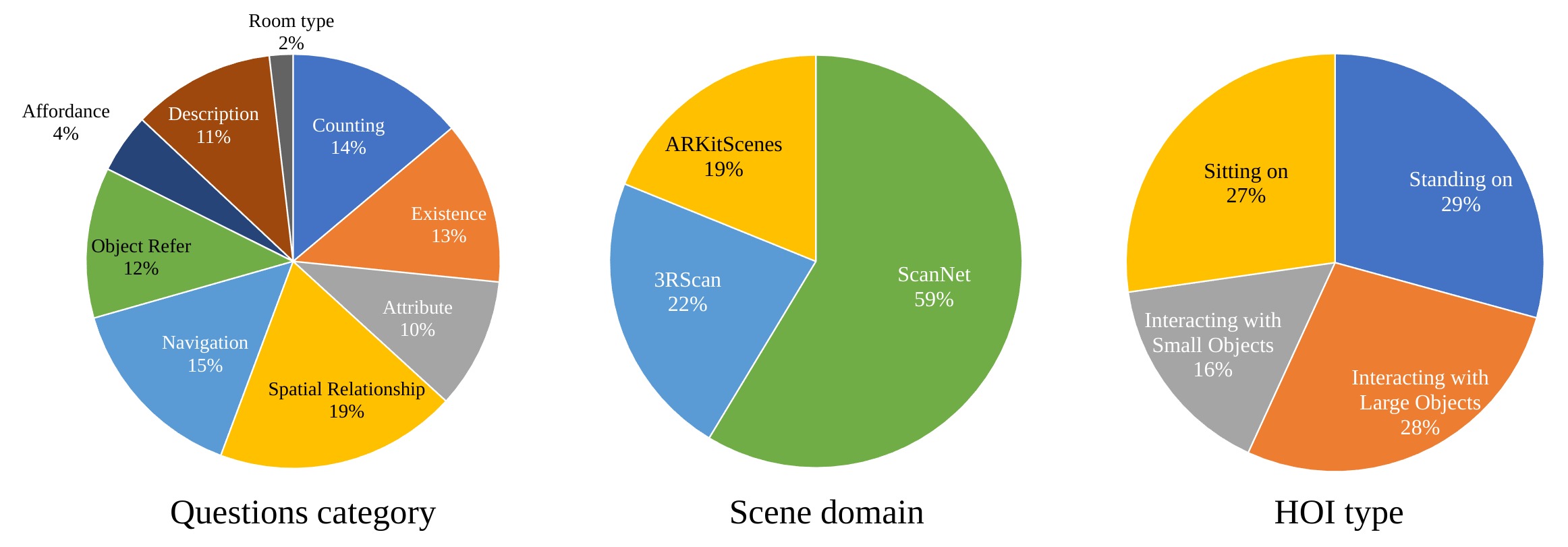
Data Distribution
Question distribution of MSQA.
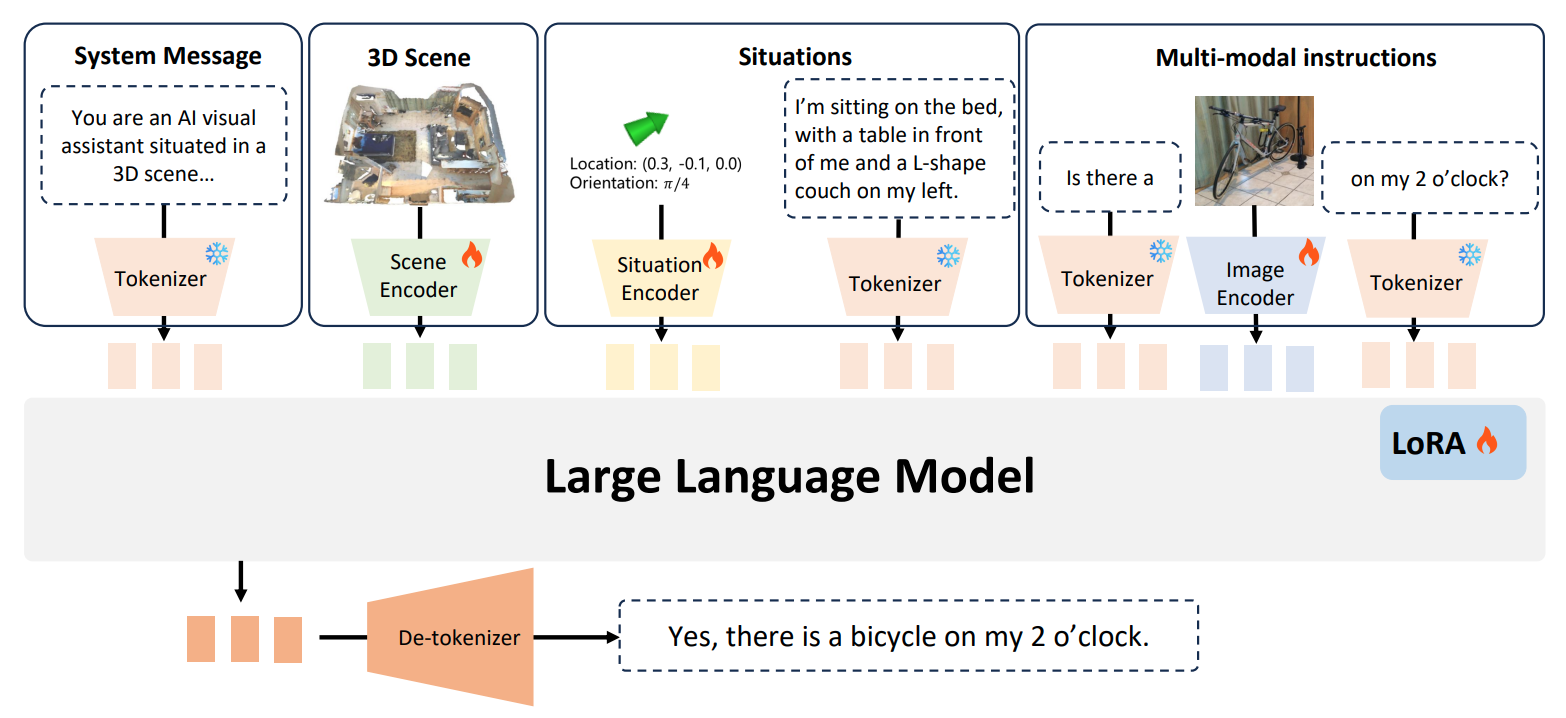
MSR3D
MSR3D accepts 3D point cloud, text-image interleaved situation, location and orientation and question as multi-modal input.
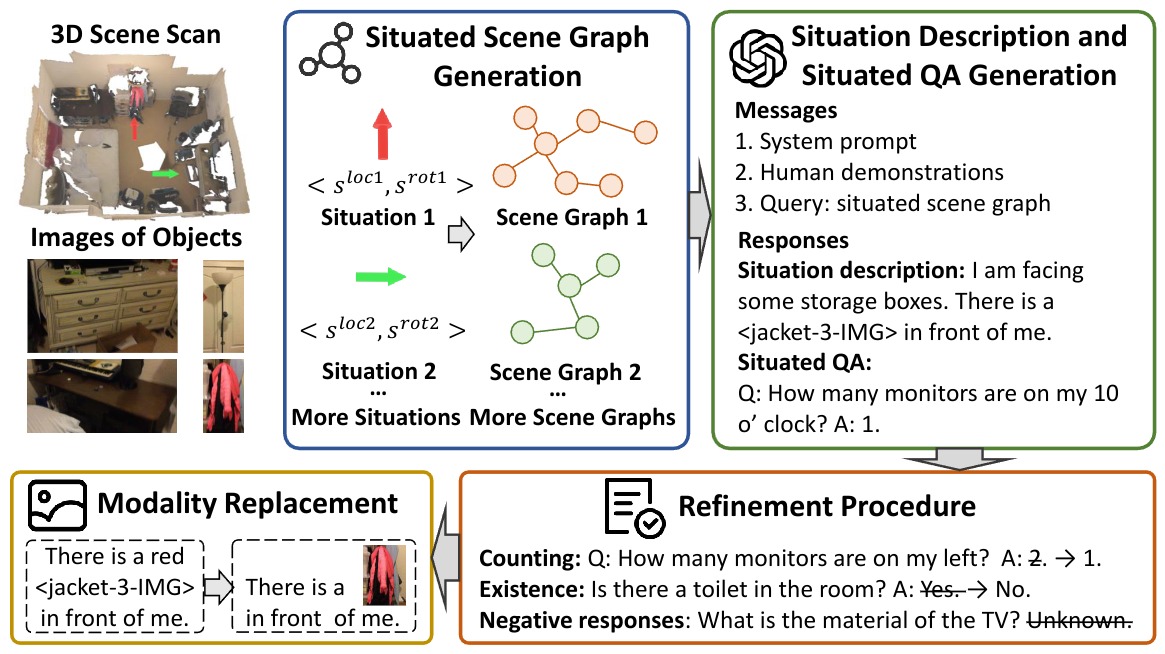
Data Collection Pipeline
An overview of our data collection pipeline, including situated scene graph generation, situated QA pairs generation, and various post-processing procedures.
Data Sample
Scene
Situation
Situation
Question
Note: Click the select dropdown to select a scene and a corresponding situation in the scene. Drag to move your view around.
BibTeX
@inproceedings{linghu2024msr3d,
author = {Linghu, Xiongkun and Huang, Jiangyong and Niu, Xuesong and Ma, Xiaojian and Jia, Baoxiong and Huang, Siyuan},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {140903--140936},
publisher = {Curran Associates, Inc.},
title = {Multi-modal Situated Reasoning in 3D Scenes},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/feaeec8ec2d3cb131fe18517ff14ec1f-Paper-Datasets_and_Benchmarks_Track.pdf},
volume = {37},
year = {2024}
}